





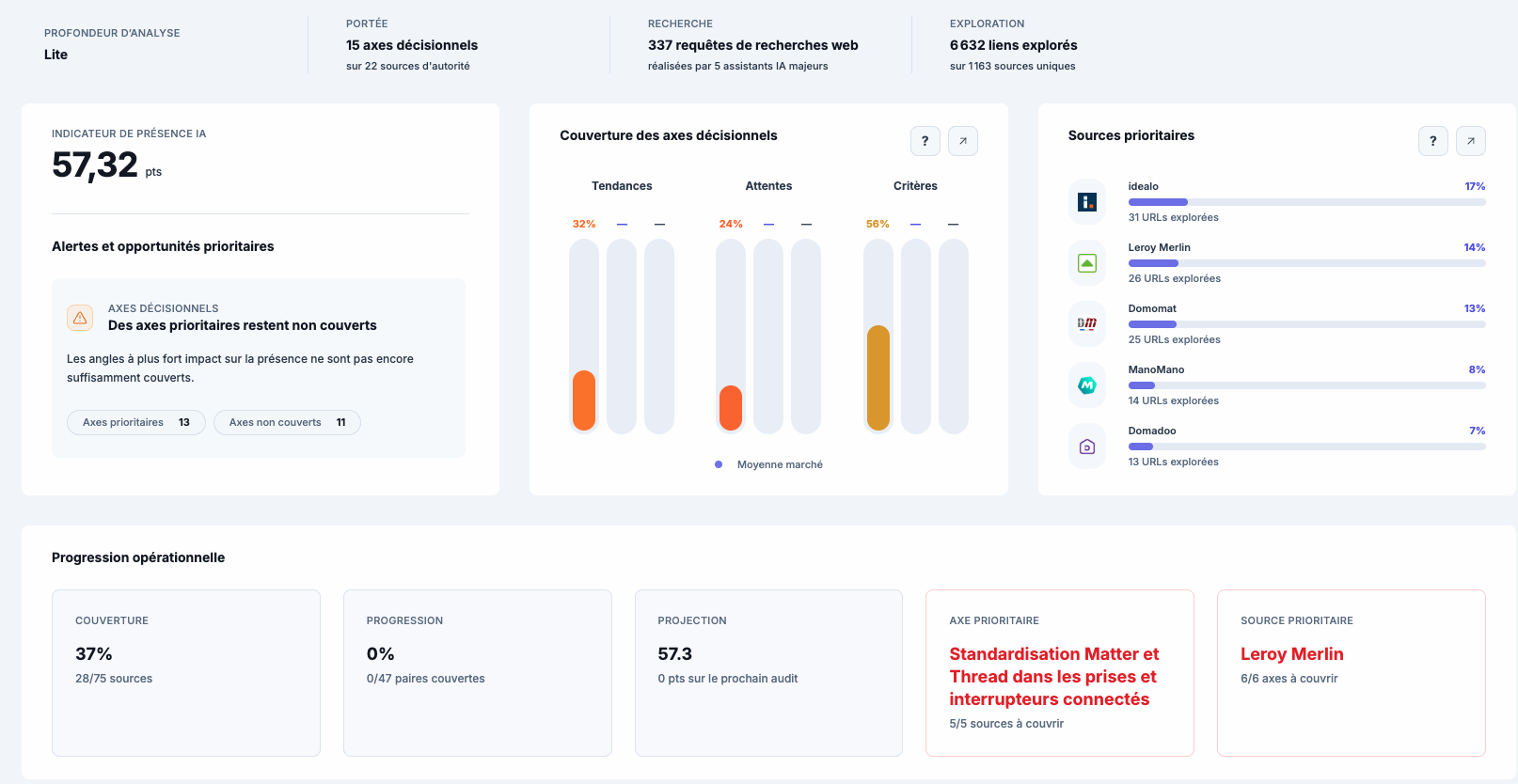
Quiz · Valide tes acquis GEO & GEA
14 questions pour tester ce que tu sais vraiment sur la transition SEO → moteurs de réponse IA et la pub native dans ChatGPT/Perplexity. Score sur 14, classement, et explication détaillée après chaque réponse.
TL;DR
Vous cherchez un outil pour mesurer votre visibilité dans ChatGPT, Perplexity ou Google AI Overviews. La SERP vous ressort 10 comparatifs d'outils de prompt tracking (Otterly.ai, Profound, Peec AI, Scrunch AI, Rankscale, Meteoria, et des dizaines d'autres). Or le prompt tracking vous dit uniquement si vous êtes mentionné. Il ne vous dit pas pour quelle raison vous êtes ou vous n'êtes pas recommandé. C'est exactement ce qu'on essaie de répondre avec la méthode qu'on utilise chez Botanik : pas un score, mais une carte des axes décisionnels que les IA utilisent pour arbitrer entre vous et vos concurrents.
Tout le monde vend du prompt tracking : voici pourquoi ce n'est pas la solution
Tapez "mesurer visibilité marque IA" dans Google. Vous tombez sur 200 outils, 50 acronymes (AEO, GEO, LLMO, AI Visibility, prompt tracking, share of model). La quasi-totalité du marché vend du prompt tracking : Otterly.ai, Profound, Peec AI, Scrunch AI, Rankscale, Meteoria, HubSpot AEO Grader, Ahrefs Brand Radar, Semrush AI Visibility Toolkit, sans compter les dizaines d'outsiders qui sortent chaque mois. C'est le langage par défaut du marché en 2026, et c'est exactement là que se loge le piège.
Si vous êtes directeur ou directrice marketing, ou si vous êtes directeur ou directrice en communication, c'est sur la base de ce que vous raconte un outil de prompt tracking que vous allez arbitrer un budget IA dans les prochains mois. Avant de signer cet abonnement, il faut que vous compreniez les raisons pour lesquelles le prompt tracking n'est pas une solution pour prendre les bonnes décisions stratégiques. Pas par opposition principielle. Par limite structurelle.
Ce que le prompt tracking ne sait pas faire
Le prompt tracking fait ce pour quoi il a été conçu : il observe les outputs des IA à un instant T, sur un grand volume de cas, et il vous livre un pourcentage. "Vous êtes mentionné dans 12% des réponses sur tel sujet." Très bien. Mais sur tout ce qui vous servirait à arbitrer une vraie décision stratégique, il s'arrête. Il ne cartographie pas les axes décisionnels que l'IA utilise pour choisir une marque plutôt qu'une autre sur votre thématique. Il n'identifie pas les sources d'autorité que le modèle consulte pour parler de votre secteur. Il ne localise pas précisément l'écart : qu'est-ce qui vous manque, où, et pourquoi. Il ne vous livre pas de recommandations d'actions priorisées et défendables. Vous obtenez un score, pas un plan d'action.
Le piège des modèles obsolètes
Et au-delà des limites fonctionnelles, il y a une limite plus dérangeante : la majorité des outils de prompt tracking interrogent des modèles obsolètes. Pas par choix méthodologique, par contrainte économique. Faire tourner des milliers de prompts en boucle plusieurs fois par jour sur un modèle récent comme GPT-5.4 (celui qui équipe par défaut l'interface payante de ChatGPT) coûte une fortune. Des analyses récentes du secteur estiment que le tarif des offres de prompt tracking devrait augmenter en moyenne de 2 500% pour supporter les modèles post-GPT-5.5. Aucun outil ne peut tenir cette équation à 29€ ou 75€ par mois. Donc la majorité du marché, y compris les acteurs nommés plus haut, interroge des versions antérieures, moins chères, dont vos clients ne se servent plus.
Concrètement : votre client qui tape sa question dans ChatGPT parle à GPT-5.4. L'outil qui mesure votre visibilité parle probablement à GPT-4o, voire GPT-3.5 sur les abonnements les moins chers. Les réponses ne sont pas les mêmes. Vous payez pour mesurer une expérience que vos clients ne vivent pas.
Le modèle change pendant qu'on le mesure
À cette instabilité méthodologique s'ajoute une instabilité structurelle : le modèle change pendant qu'on le mesure. Une même question tapée deux fois à 10 minutes d'écart par deux utilisateurs différents produit deux réponses structurellement distinctes. La micro-variation dans la formulation, l'historique du compte, la localisation, l'heure : tout modifie le résultat. Vous n'avez pas un instrument de mesure stable. Vous avez une photographie partielle qui change à chaque clic.
C'est cette double limite (robustesse faible aux variations + modèles décalés vs réalité utilisateur) qui rend le prompt tracking inexploitable pour décider d'une stratégie. Pour la mesurer après coup, à la limite. Pour la construire, non.
Avantages et inconvénients : prompt tracking vs analyse conversationnelle
Pour clarifier, voici une lecture côte à côte des deux approches sur ce qui compte vraiment au moment d'arbitrer un budget.
Fonctionnalité | Prompt tracking (Otterly, Profound, Peec, Scrunch, Rankscale, Meteoria, etc.) | Analyse conversationnelle (méthode Botanik) |
|---|---|---|
Observation des outputs à un instant T | Oui | Oui |
Tests rapides sur grand volume de cas | Oui | Oui |
Robustesse aux variations de formulation | Limitée | Forte |
Cartographie des axes décisionnels du marché | Non | Oui |
Identification des sources d'autorité que l'IA consulte | Non | Oui |
Couverture observée avec preuve à l'appui | Partielle | Oui |
Localisation précise de l'écart : quoi corriger, où, pourquoi | Non | Oui |
Recommandations d'actions priorisées et défendables | Non | Oui |
Analyses alignées avec les modèles récents | Anciens modèles | Oui |
La plupart des outils de prompt tracking s'appuient sur des versions obsolètes des modèles de langage, moins coûteuses que celles réellement utilisées dans les interfaces grand public. Suivre des milliers de prompts sur les modèles les plus récents n'est pas financièrement soutenable au tarif marché actuel.
Lecture rapide du tableau : le prompt tracking est utile pour mesurer après coup ce qui se passe à un instant T. L'analyse conversationnelle est utile pour comprendre pourquoi ça se passe, et donc pour décider quoi corriger. Les deux ne s'opposent pas frontalement, mais ils ne répondent pas à la même question. Si votre question est "quel budget je mets dans le GEO ce trimestre, sur quels axes, avec quel ROI attendu ?", le prompt tracking est insuffisant.
Mesurer, évaluer, suivre, analyser : peu importe le verbe, c'est trois états qu'il faut regarder
Quand un dirigeant nous demande comment évaluer la notoriété de sa marque dans ChatGPT, Gemini ou AI Mode, il pose la mauvaise question. La bonne, c'est : ma marque est-elle absente, mentionnée ou recommandée par ces IA ? Que vous parliez de mesurer, d'évaluer, de suivre, d'analyser ou de vérifier votre visibilité IA, le verbe importe peu. Ce qui compte, c'est ce que vous regardez.
Avant de parler de la méthode qu'on utilise, il faut désapprendre un réflexe SEO. Il n'y a pas de "position" dans une réponse d'IA. Pas de top 10, pas de page 2, pas de classement. Une IA ne vous ressort pas une liste de liens. Elle vous donne une seule réponse, et soit vous êtes dedans, soit vous n'y êtes pas.
Mentionné, Recommandé, Absent
Du coup, la métrique utile ne s'exprime pas en position. Elle s'exprime en 3 états, et notre slogan tient en deux mots : Mention ≠ Recommandation.
Mentionné : votre nom apparaît dans la réponse, dans une liste, dans une comparaison, dans une phrase de contexte. Vous existez aux yeux du modèle.
Recommandé : l'IA vous met en avant. Elle vous cite en premier choix. Elle vous conseille explicitement. C'est l'équivalent IA d'être en position 1 organique, sauf qu'il n'y a pas de position 2.
Absent : votre nom n'apparaît nulle part. Comme si vous n'existiez pas. C'est la situation par défaut pour 95% des marques B2B aujourd'hui en France.
Et sur Google AI Mode, ça marche pareil ?
Oui. AI Mode reprend la même logique que ChatGPT, Perplexity ou Gemini : il construit une réponse, il cite des sources, et il choisit qui il recommande. La trilogie absente / mentionnée / recommandée s'applique exactement de la même façon. La seule chose qui change, c'est l'enjeu : AI Mode tourne déjà sur plus d'un milliard d'utilisateurs mensuels selon Google, avec des requêtes en moyenne 3 fois plus longues qu'en Search classique. Du coup, suivre la visibilité de votre marque dans AI Mode, c'est suivre une part croissante du trafic Google lui-même, pas un canal alternatif. Vérifier si votre marque est citée dans AI Mode est devenu aussi important que de vérifier votre position SERP il y a dix ans.
Pourquoi cette distinction n'est pas cosmétique
Un de nos clients revendeur de matériel électrique audité l'an dernier : 20% de mention, 0% de recommandation, 80% d'absence. Si vous regardez uniquement la mention, vous pourriez vous dire "ça va, je suis dans 1 réponse sur 5". Si vous regardez la recommandation, le constat est brutal : zéro. Le modèle vous connaît mais ne vous pousse jamais. C'est un problème complètement différent à résoudre. Le premier appelle de la notoriété supplémentaire. Le second appelle des preuves de différenciation que l'IA n'a pas trouvées dans les sources qu'elle consulte sur votre sujet.
Concrètement, quand vous construisez votre tableau de mesure, oubliez le score global "X% de visibilité". Vous voulez 3 colonnes. Vous voulez savoir où vous existez, où vous êtes recommandé, et où vous êtes absent. Trois leviers, trois plans d'action différents.
La méthode qu'on utilise chez Botanik : l'analyse conversationnelle
Cette méthode ne s'appelle pas prompt tracking amélioré. On l'appelle analyse conversationnelle. C'est une techno propriétaire qui reconstitue le raisonnement et la logique de recommandation des assistants IA en situation réelle.
Le principe tient en une phrase. Le prompt tracking observe les sorties. L'analyse conversationnelle reconstruit le raisonnement. On ne cherche pas à savoir si vous êtes mentionné. On cherche à comprendre pourquoi vous l'êtes ou pas, et surtout à isoler ce qu'il faut bouger pour que ça change.
Le process : 5 étapes, pas 1
Là où un outil de prompt tracking tape votre requête en boucle et vous ressort un pourcentage, on déroule un process structuré en 5 étapes.
Cadrage. On définit la thématique, le périmètre concurrentiel, les sous-sujets qui comptent vraiment pour votre business. Pas "votre site dans son ensemble" mais une thématique précise, parce qu'au-delà de ce périmètre, l'IA ne raisonne plus pareil.
Modélisation. On configure les conversations IA-IA qu'on va lancer, avec des prompts techniques qui font plusieurs méga-octets et qui définissent l'environnement de raisonnement à observer. Ces prompts adaptent en temps réel les questions posées à l'IA testée, en fonction de ses propres réponses. C'est ce qui sépare une vraie analyse d'un benchmarking de surface.
Extraction des axes décisionnels. Pour chaque thématique, l'IA arbitre entre les marques selon un nombre limité de critères, typiquement 10 à 15 axes. On les identifie un par un : actualité du sujet, profondeur d'expertise perçue, présence dans les sources de référence, alignement avec les attentes utilisateur. Ce sont les vrais leviers de recommandation, pas des indicateurs de surface.
Extraction des sources d'autorité. Sur chaque axe, on isole les sources que l'IA consulte réellement pour construire sa réponse. Ce ne sont presque jamais les sites des marques, mais des médias spécialisés, des forums professionnels, Wikipédia, Reddit, LinkedIn, des annuaires sectoriels. Vous saurez précisément où il faut être présent et avec quels termes.
Consolidation, prompts activateurs, identification des concurrents, audit de couverture, scoring. Les quatre dernières étapes formalisent le résultat. Au passage, on identifie les vrais concurrents sans qu'on vous demande de les renseigner : sur tous les audits qu'on a menés, les concurrents que la méthode remonte automatiquement correspondent aux concurrents réels du client.
Sur quel modèle on audite
On audite sur GPT-5.4. À notre connaissance, aucun autre outil de prompt tracking ne le fait. Pas par snobisme, par cohérence avec l'expérience utilisateur réelle. Si vos clients utilisent l'interface payante de ChatGPT, on mesure ce qu'ils vivent, pas ce que coûte le moins cher à interroger en boucle.
Sur les biais de raisonnement thématique, les modèles convergent. Gemini, Claude et ChatGPT donnent des conclusions très proches une fois qu'on cherche le pourquoi plutôt que les positions. Les variations entre LLMs sur le raisonnement de fond sont marginales. C'est pour ça qu'on concentre le gros de l'audit sur le modèle le plus récent, avec des vérifications croisées plutôt qu'une dispersion équivalente sur tous les moteurs.
Ce qu'on ne prétend pas faire
On publie nos anti-garanties parce qu'elles sont à la fois honnêtes et structurellement importantes pour cadrer ce que la méthode peut et ne peut pas faire.
On ne dispose pas des vrais prompts tapés par les utilisateurs finaux des assistants IA. Personne ne les a. On ne garantit pas la recommandation systématique dans tous les contextes, l'IA reste un système non déterministe. On ne manipule pas les réponses des assistants IA par des biais douteux. On ne remplace pas le travail SEO classique : on ajoute une couche, on ne substitue pas. On ne prédit pas chaque réponse IA avec une fiabilité sans failles. Et on n'exécute pas les actions recommandées à votre place : on cartographie, on priorise, on justifie. La mise en œuvre, c'est votre équipe ou nous en accompagnement, mais c'est une étape distincte de l'audit.
C'est une posture rare dans le GEO français en 2026, où la sur-promesse est devenue la norme. Notre thèse de fond résume bien l'esprit : les modèles de langage évoluent avec le web public. Ce qu'on publie aujourd'hui nourrit les modèles de demain. La logique n'est pas de truquer le système, c'est de comprendre comment il s'alimente pour s'y inscrire durablement.
Ce que vous obtenez à la sortie d'un audit
Concrètement, à la fin d'un audit, vous ne recevez pas un dashboard "vous êtes à 12%". Vous recevez 7 grandes pages structurées :
Tableau de bord : la situation actuelle de votre marque par rapport au marché sur la thématique auditée.
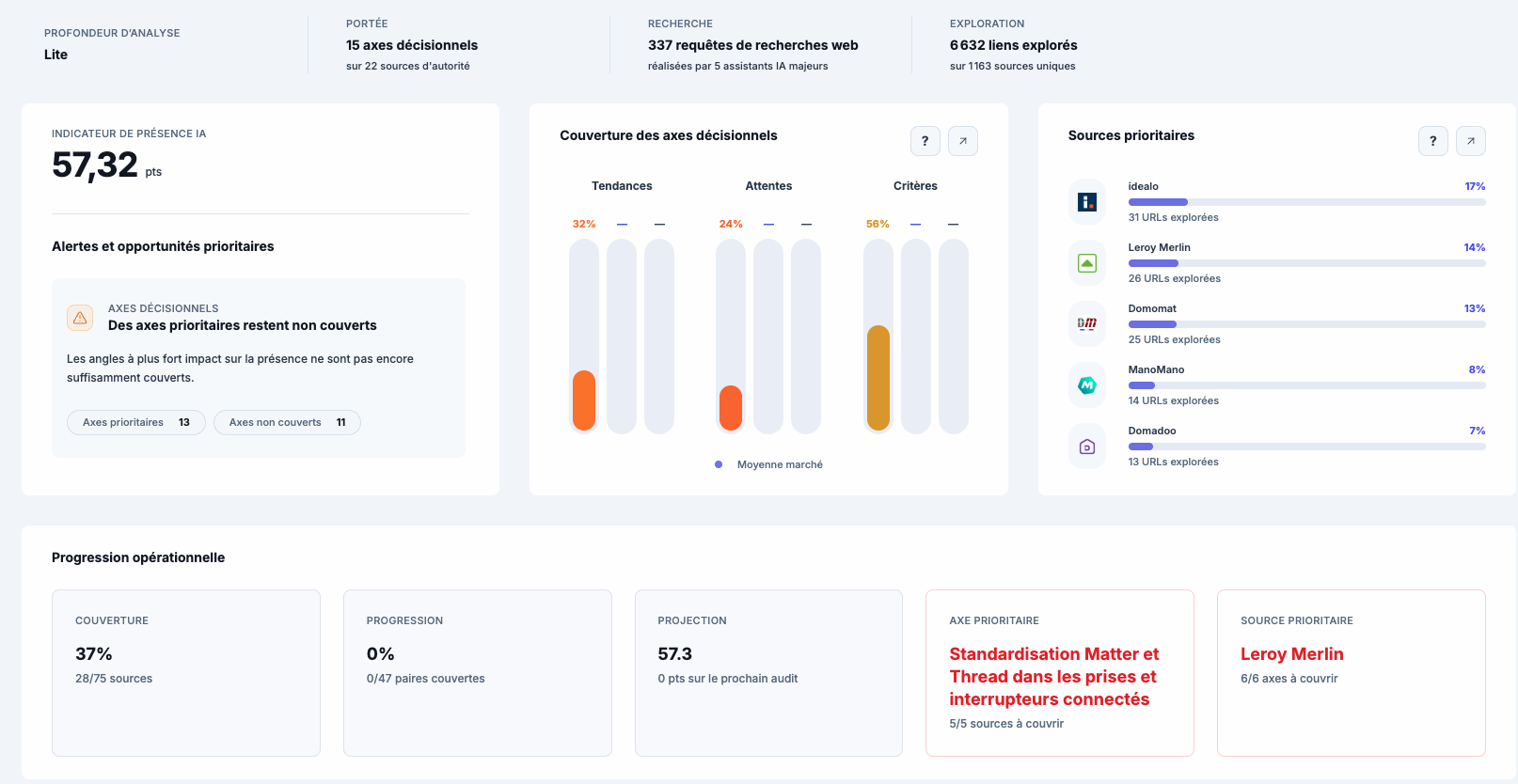
Axes décisionnels : pour chaque critère que l'IA utilise, votre couverture, votre position par rapport aux concurrents, et l'écart à combler. C'est la page qui vous dit quoi faire.
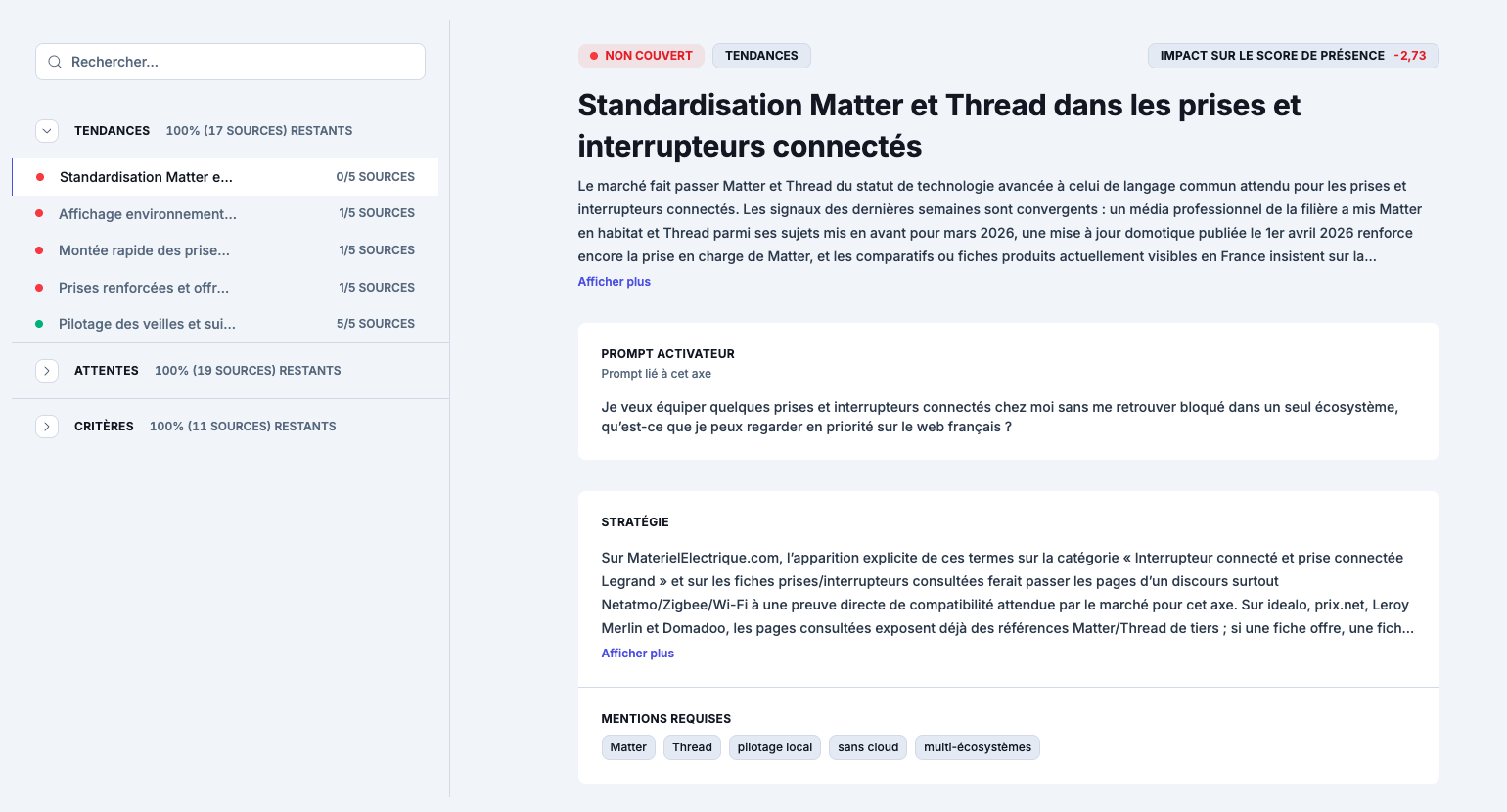
Sources d'autorité : les pages précises (pas les domaines, les URLs exactes) sur lesquelles l'IA consulte pour parler de votre sujet.
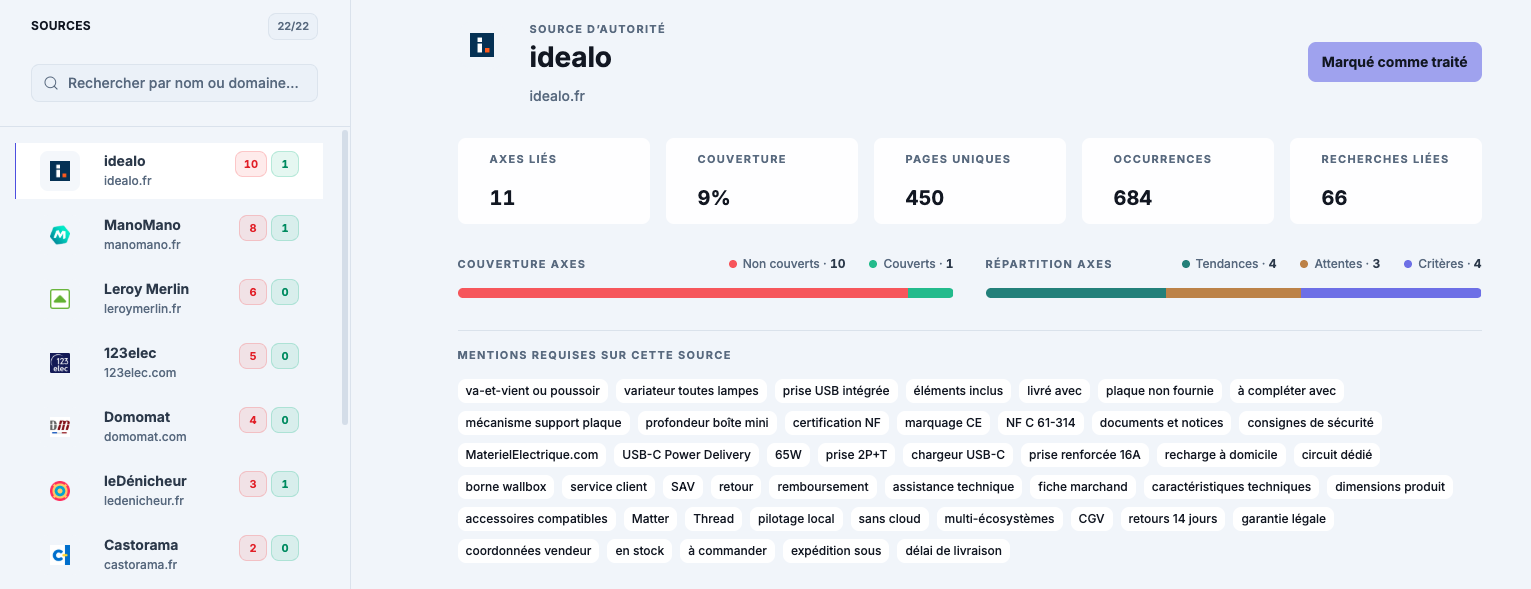
Requêtes : les prompts activateurs et leurs réponses analysées.
Recherches : les patterns de fan-out, c'est-à-dire les recherches dérivées que l'IA fait derrière chaque prompt utilisateur.
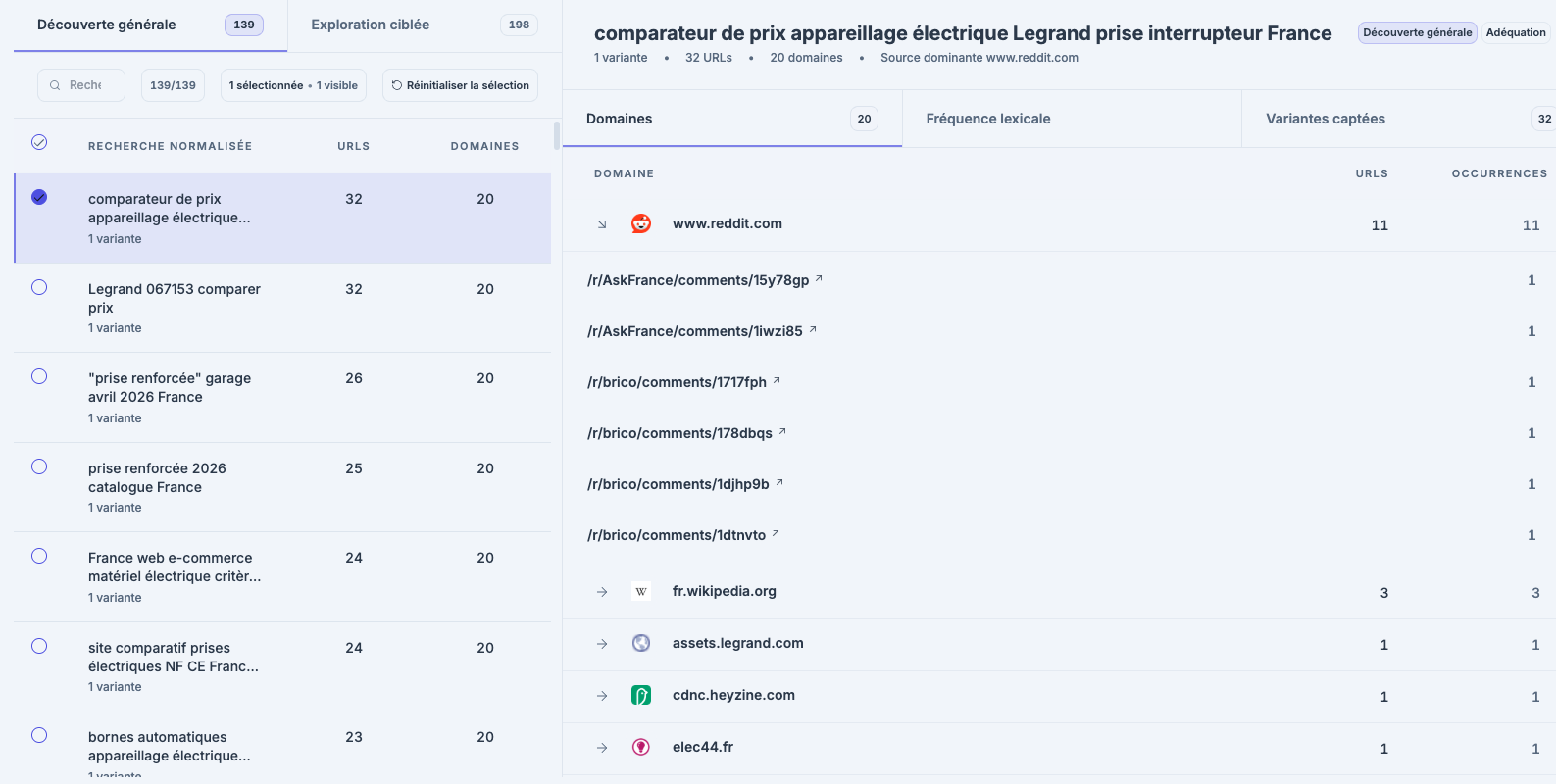
Concurrence : la cartographie des marques que l'IA identifie comme alternatives sur la thématique.
Navigation : la structure de tout ça en parcours actionnable.
L'écart avec un outil de prompt tracking ne se mesure pas en quantité, mais en qualité de décision. Avec un score "12% de visibilité", vous savez que vous avez un problème. Vous ne savez ni où, ni pourquoi, ni dans quel ordre traiter. Avec une cartographie des axes décisionnels, vous avez un plan de bataille trimestriel avec des objectifs précis par axe et des sources précises sur lesquelles agir.
Et derrière, on accompagne : un expert par axe
L'audit vous livre le diagnostic et la priorisation. Mais l'objectif réel, c'est de réduire l'écart avec vos concurrents sur les axes où vous perdez aujourd'hui. C'est là qu'on bascule sur l'accompagnement post-audit, étape distincte de l'audit lui-même.
Pour chaque axe prioritaire identifié, on mobilise un expert sur le bon canal. Trois expertises sont éprouvées chez nous sur tous nos accompagnements : SEO classique pour reposer les fondations techniques et le contenu sur votre site, GEO pour aller travailler les sources tierces que l'IA consulte sur votre thématique (médias spécialisés, Wikipédia, annuaires sectoriels, plateformes B2B), et YouTube SEO quand les vidéos longues dominent les réponses IA sur votre secteur, ce qui devient fréquent en B2B et en achat considéré.
Pour les autres canaux que votre audit ferait remonter comme prioritaires (Discover, Pinterest, Reddit, LinkedIn organic, forums professionnels), on mobilise selon le besoin via notre réseau de spécialistes éprouvés. Chaque axe appelle un type d'action différent, et un consultant SEO généraliste ne sait pas faire toutes ces choses correctement.
On n'envoie pas non plus une équipe sur tout en même temps. On priorise par gradient : l'axe où le gap concurrentiel est le plus large ET où le volume de mention est le plus fort passe en premier. C'est ce qui permet de livrer des résultats mesurables sur un trimestre, pas dans 18 mois. Et on documente l'uplift sur chaque axe traité, parce qu'on serait incapable de justifier la suite sinon. C'est cohérent avec la méthode "preuve avant budget" qu'on applique aussi sur le SEO classique.
Comparer votre visibilité IA à celle de vos concurrents
C'est la question qui revient à chaque audit : comment je me situe par rapport à mes concurrents dans les IA ? L'analyse conversationnelle vous donne ça directement. Oracle identifie automatiquement les concurrents que les LLMs vous perçoivent comme alternatives (souvent pas ceux que vous surveillez), mesure leur part de voix sur votre thématique, et révèle quelles requêtes ils captent à votre place. Identifier la fréquence de mention de chaque acteur, vérifier qui est cité, dans quel contexte, avec quels arguments : vous avez le tableau complet. C'est cette photo concurrentielle qui rend possible le plan d'action.
Comment évaluer un prestataire ou un outil IA sérieux
Si vous êtes en train d'évaluer plusieurs options (outils en self-service, plateformes SaaS, agences GEO), posez ces 4 questions et regardez la qualité de la réponse. Elles filtrent 80% du marché.
1. Sur quel modèle exact interrogez-vous l'IA, et le précisez-vous publiquement ? Si la réponse n'est pas claire ou si l'outil interroge GPT-4o pendant que vos clients utilisent GPT-5.4, vous mesurez un proxy, pas la réalité. Ça ne veut pas dire que l'outil est inutile, mais vous devez le savoir avant de signer.
2. Cherchez-vous via API ou simulez-vous l'interface utilisateur ? L'API ne reproduit pas ce que votre client vit. Les outils ou méthodes qui passent par la simulation d'usage réel sont plus proches de la vérité : plus chers, plus lents, plus justes.
*3. Me livrez-vous un pourquoi ou seulement un score ?* Un dashboard "vous êtes à 12%" est inutile sans le pourquoi. Une méthode qui vous donne les axes décisionnels et les sources d'autorité vous livre un plan d'action. Le premier est une vanity metric. Le second est un outil de pilotage.
4. Votre méthode est-elle publiée, ou seulement votre dashboard ? Méfiez-vous des solutions qui n'expliquent pas comment elles mesurent. Posez la question en démo : "sur quel modèle interrogez-vous, à quelle fréquence, depuis quelle géolocalisation IP, avec quel type de compte, et selon quel process structuré ?". Si la réponse est vague ou si vous recevez un PDF marketing au lieu d'une réponse technique, vous savez à quoi vous en tenir.
Et après
Si vous voulez voir ce que ça donne sur votre marché, on fait des audits sur une thématique précise, pas "votre site dans son ensemble". On vous présente un audit réel anonymisé en 15 minutes et vous voyez exactement le format de livrable et le niveau de détail. À vous de juger si c'est ce dont vous avez besoin pour votre prochaine décision IA, ou pas.
Questions fréquentes
Pourquoi Botanik refuse-t-il de faire du prompt tracking comme tout le monde ?
Pour deux raisons structurelles. La première, c'est que le prompt tracking observe les outputs sans expliquer le raisonnement. Il décrit un symptôme sans donner le diagnostic ni le traitement. La seconde, c'est que les outils du marché (Otterly, Profound, Peec, Scrunch, Rankscale, Meteoria et les autres) tournent majoritairement sur des modèles obsolètes pour des raisons économiques : le tarif viable d'un outil de prompt tracking ne couvre pas l'API des modèles récents, il faudrait multiplier les prix par environ 25 pour suivre les modèles post-GPT-5.5. Ce qui veut dire que vous payez pour mesurer une expérience que vos clients ne vivent pas. On a fait un autre choix : moins de prompts, mieux interrogés, sur le bon modèle, pour reconstruire le pourquoi.
Qu'est-ce que l'analyse conversationnelle exactement ?
C'est notre techno propriétaire. Au lieu d'interroger l'IA avec un prompt isolé pour voir si vous apparaissez dans la réponse, on lance des conversations multi-tour pilotées par un modèle propriétaire qui adapte ses questions en temps réel selon les réponses obtenues. C'est ce qui permet d'isoler les axes décisionnels : les critères que l'IA utilise pour arbitrer entre les marques sur une thématique. On reconstruit la logique de recommandation, pas juste la sortie de surface.
Est-ce que le SEO classique sert encore à quelque chose ?
Oui. La corrélation entre top 10 SEO et citation par les IA est passée de 76% à 38% en un an, donc le SEO ne suffit plus, mais il reste un signal. La nouvelle équation, c'est SEO classique + présence sur les sources tierces que l'IA consulte (Wikipédia, Reddit, LinkedIn, médias spécialisés, annuaires sectoriels) + cohérence des mentions de marque sur ces sources. Un site bien classé sans mentions cohérentes ailleurs est aujourd'hui invisible pour les IA. L'analyse conversationnelle ne remplace pas le SEO, elle s'ajoute par-dessus en disant où et comment travailler les sources tierces.
Combien de temps prend un audit d'analyse conversationnelle ?
L'audit est livré sous environ 24 heures à partir du moment où le cadrage est validé. La phase de cadrage avec le client prend généralement 1 à 2 séances pour bien définir la thématique, le périmètre concurrentiel et les axes d'arbitrage prioritaires. C'est volontairement court parce qu'un audit qui prend 3 mois n'est plus exploitable : les modèles bougent, le marché bouge, l'angle d'attaque doit être validé vite.
Faut-il faire du contenu spécifique pour les IA ?
Pas du contenu spécifique, mais du contenu structuré pour être réutilisé par les modèles. Ça veut dire : titres clairs avec la question dans le H2, réponses denses dans les premiers paragraphes, données chiffrées avec leur source explicite, mentions cohérentes de votre marque dans des contextes utiles. Les IA ne réutilisent pas du contenu vague, elles réutilisent des unités de raisonnement structurées : chiffres, définitions, comparaisons précises. La nuance importante : ce contenu structuré doit aussi exister sur les sources tierces que l'IA consulte, pas juste sur votre site.
Le tracking IA va-t-il remplacer le SEO traditionnel ?
Non. Le SEO classique continue d'exister parce que les moteurs de recherche traditionnels continuent d'être utilisés, particulièrement sur les requêtes à forte intention d'achat. L'analyse conversationnelle s'ajoute, elle ne remplace pas. La bonne posture aujourd'hui pour une direction marketing, c'est de continuer à investir sur le SEO classique tout en commençant à investir sur la visibilité dans les LLMs, parce que vos concurrents directs ne le font pas encore. La fenêtre d'opportunité est ouverte 12 à 18 mois, pas davantage. Au-delà, le retard sera structurel.
Outils comme Ahrefs Brand Radar, Semrush AI Visibility Toolkit, HubSpot AEO ou Otterly : qu'est-ce qu'on en pense ?
Ce sont tous des outils de prompt tracking, plus ou moins bien intégrés à des suites SEO existantes. Pour du monitoring d'exposition rapide, ils font le job. Pour comprendre pourquoi votre marque est recommandée ou pas, ils sortent du périmètre. On en a parlé en détail dans notre comparatif des alternatives à Botrank, qui passe au crible une douzaine de ces outils.
Comment vérifier rapidement si ma marque est citée dans ChatGPT ou AI Mode ?
Tapez vous-même la requête que vos prospects taperaient, sans être connecté à votre compte si possible. Vous voyez si votre nom sort. C'est zéro coût, c'est imparfait (les deux biais qu'on cite plus haut, API ≠ interface et variabilité utilisateur), mais ça donne une photo en 5 minutes. Pour quelque chose de fiable et reproductible, il faut passer à de l'analyse conversationnelle.